

Centralized v. Decentralized AI Governance
How to choose which approach is right for your marketing organization


There’s a lot of talk in marketing circles right now about whether AI implementation and governance should be centralized or decentralized. Most recently, I was listening to a podcast featuring Owner.com CRO Kyle Norton arguing strongly in favor of a centralized approach. Kyle is an accomplished revenue leader with an incredible track record. When he talks about how Owner is approaching AI, he makes a compelling case — and Owner.com’s results are arguably the best rationale for why this approach makes sense.
At the same time, I’ve seen firsthand how powerful AI can be when the people closest to the work use it to find solutions to their own problems. They have deep, first hand knowledge of the jobs to be done and are feeling the pain of inefficiency on a daily basis. This makes them uniquely suited to building solutions that will solve the problem, quickly. But, it also stands to reason that you might not want them spending a lot of their time building things with AI when they should be doing their day-to-day work.
I think the question of whether to centralize or decentralize ownership of AI implementation is an interesting one, and the answer isn’t necessarily as black and white as you might think.
A better question might be, “What specifically needs to be centralized, and what specifically needs to be owned by the people doing the work?”
Getting that distinction right — in practice, for your team, at your current stage of growth — may be the most important structural decision you make about AI in the next two years.
Get it wrong in one direction and you end up with a compliance nightmare, a bunch of disconnected tools, and tribal knowledge that’s at risk of being lost every time someone leaves the company.
Get it wrong in the other direction and you’ve built a governance apparatus that slows your team down unnecessarily at a time when AI is evolving quickly and competition is fierce.
As I build the marketing team at Sequel, this is top of mind for me, and this issue is an attempt to think through that question rigorously rather than relying on purely anecdotal insights. I’m going to cite actual research, name real companies, and share my own point of view — which I’ll be upfront about when I’m expressing it.
First, some definitions
When the research talks about “centralized AI implementation”, it means concentrating decision rights, standards, tooling, risk management, and often staffing in a single central unit — what McKinsey calls a “chief data and AI officer” structure, or what organizations sometimes label an AI Center of Excellence (CoE). In this model, the central team owns the platform, the intake process, the risk framework, and the approval workflow. Business functions like marketing consume services the central team has approved and provisioned.
Centralized AI implementation concentrates decision rights, standards, tooling, risk management, and staffing in a single central unit
When the research talks about “decentralized AI implementation”, it means placing use-case ownership inside the business function itself. The marketing team owns its backlog of AI projects, its local data, its testing, and often its day-to-day operations. The center, if it exists, acts more as a standards body for the company than a delivery team.
Decentralized AI implementation places use-case ownership inside the business function itself
Between these two ends of the spectrum sits what most researchers and practitioners describe as the “federated model”: a central team that owns shared infrastructure, common standards, and governance, while domain teams — marketing, sales, service, product — own use-case design, workflow integration, and KPI measurement.
In a federated model, a central team owns shared AI infrastructure, common standards, and governance, while domain teams own use-case design, workflow integration, and KPI measurement
McKinsey describes the evolution of AI operating models as a progression from centralized, to federated, and eventually more decentralized execution. BCG makes the same point from the governance side, arguing that governance design should be treated as a spectrum rather than a binary choice.
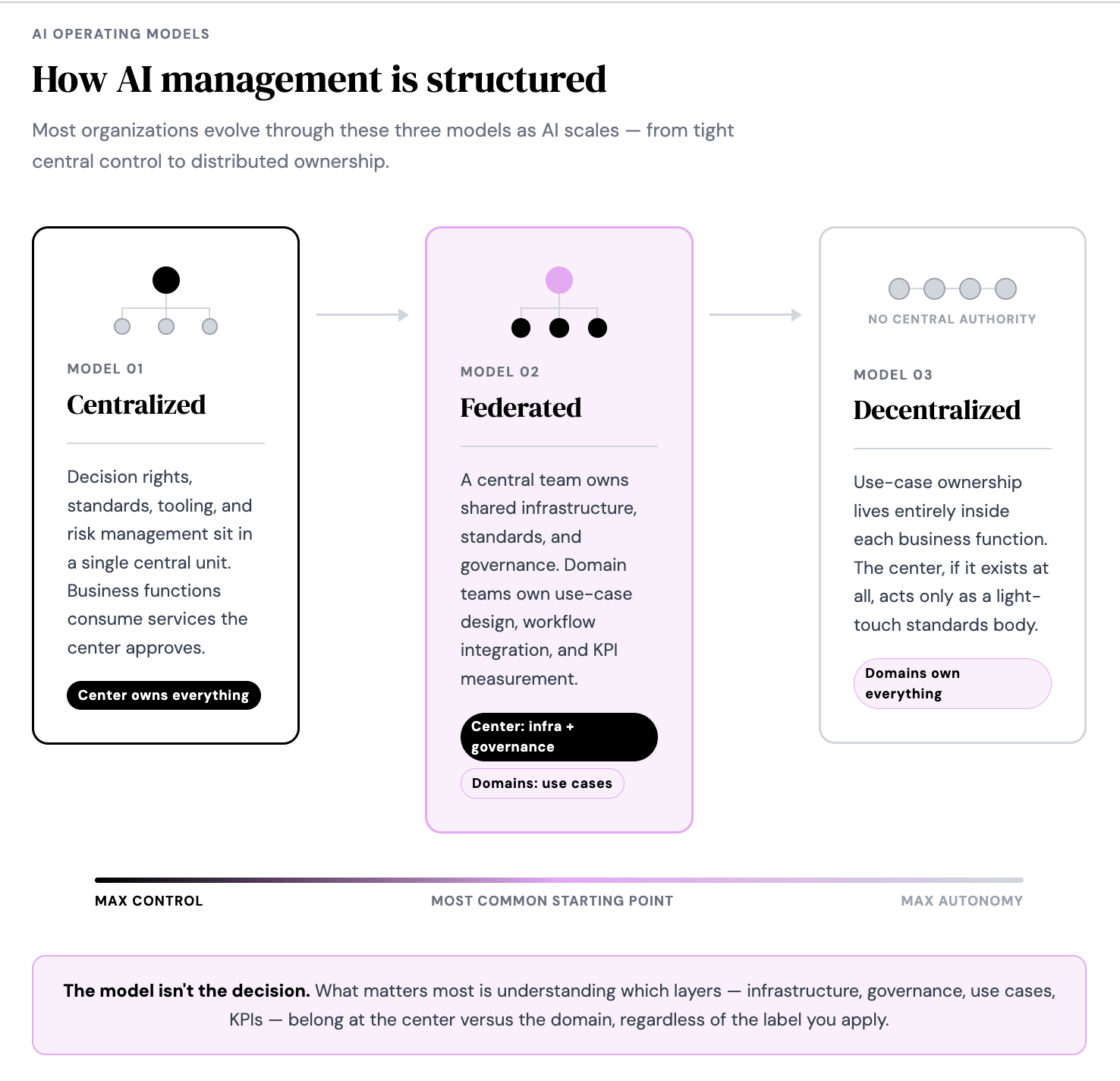
While all of this sounds straightforward in theory, the distinction that matters most for marketing leaders isn’t which label applies. It’s understanding which layers belong where — and that’s a more nuanced question than most frameworks acknowledge.
What the research actually says
There’s quite a bit of academic literature and research on centralized versus decentralized AI, but very few controlled, head-to-head comparisons of the two operating models across the same organizations over time. Most published evidence comes from executive surveys, engineering case studies, and research produced by consulting firms with an inherent bias.
That’s important context to understand, but doesn’t necessarily mean the conclusions that have been drawn are irrelevant.
Let’s dig in…
The ROI case for centralization
BCG’s 2025 study of 300 Nordic executives found that companies operating under decentralized, or federated, models captured roughly half the AI ROI compared with those that are centralized. The researchers attributed this disparity to pilot fragmentation, meaning that decentralized ownership produced lots of experiments that never scaled, ownership spread across too many functions, and difficulty proving enterprise value.
I feel like we’ve all seen this play out. It’s the scenario where a marketing team builds a great content workflow, a BDR team builds a great prospecting tool, and neither ever connects to anything the other is doing — so none of the value compounds. When this happens, you’ll find team members duplicating the work of others, or you’ll have pockets of efficiency that don’t translate across the team.
The downsides of centralization
Centralization sounds great, right? Not so fast.
McKinsey’s research found that centralized AI teams can become bottlenecks once use cases multiply beyond what they can easily manage and become overwhelmed when they continue to own all domain-specific data management.
Airbnb’s experience is a good example of this. The company started with a fully centralized data science model and ultimately moved to a hybrid embedded structure because, as their engineering team put it, the central team “lacked enough local context and became reactive” — a service desk for the business rather than a strategic partner.
This is what so many marketing teams, and leaders, dread. The beauty of AI is that it lets us work at unprecedented speed, eliminating previously common bottlenecks that forced us to wait for the engineering or design teams to get to our requests (which, lets be honest, were often de-prioritized in favor of product development). If the promise of AI is speed, centralization can feel like an existential threat.
The companies that are winning are separating the layers
Both centralization and decentralization have benefits but also pose risks. So, what’s the answer?
As with any good question, it’s some form of “it depends” — or, in this case, “a little of both.” That’s what the federated model is all about, and where I think most companies will probably land.
Here are some examples of companies successfully using federated AI implementation models:
Uber’s Michelangelo platform (launched in 2016) standardized end-to-end machine learning (ML) workflows and by the end of 2019 had most of Uber’s lines of business integrated, while keeping domain teams in control of their own use-case development.
Spotify built a centralized ML platform that serves more than half of its internal practitioners, while letting the marketing and product teams own their experimentation queues including an in-app messaging model that “significantly improved user retention” and stayed in production through tight domain-level A/B testing.
Netflix built Metaflow (it’s ML model) specifically to compress the time between prototype and production from weeks to hours, without re-centralizing every use case.
In each of these cases, the pattern is the same. The company has a shared AI platform and shared standards, but decentralizes the ownership of AI execution to individual teams (such as marketing) in order to prioritize speed while still reaping the benefits that come with scaled solutions.
McKinsey’s State of AI report has data that backs up the impact that federated models can have, finding that 31% of high-performing AI organizations use a component-based operating model (meaning, shared reusable AI components across teams) versus 11% of other companies. The data also shows that centralized models often slow things down, finding that only 14% of enterprise organizations can deploy a model within a week, while the rest take anywhere from eight to 90 days or longer.
The tradeoffs
As with most things, there’s not really one right answer. Here’s how I see the pros and cons of each approach.
Centralization advantages:
Lower fixed costs in early phases, because tooling, approvals, and specialist talent are shared
Faster initial deployment, particularly in regulated or compliance-heavy environments
Consistent brand safety, security controls, and auditability across everything the organization ships
Easier to enforce documentation standards and incident response protocols
Reduced risk of inefficient, parallel solutions that duplicate the same infrastructure
Centralization disadvantages:
Central teams become a bottleneck once use-case volume exceeds their capacity
Lack of context produces solutions that are technically correct but not practically useful (which leads to low or no adoption)
Slows down the teams closest to the work — the ones who are feeling the pain and understand best where the friction is
Grassroots adoption is hard to drive from the center, making the cultivation of decentralized AI “champions” crucial
Decentralization advantages:
People closest to the work build the solutions that actually fit the work
Faster iteration once teams have platform access and approval
Better adoption, because the people using the tool helped build it
Faster experimentation cadence (Booking.com scaled to 150 successful customer-facing ML applications built and validated by dozens of teams working independently using a decentralized model)
Decentralization disadvantages:
Without shared infrastructure, you get a bunch of random prompt libraries, experiments which may or may not be documented, conflicting or non-existent brand safety policies, and no reliable record of what’s in production
BCG’s Nordic study ties this kind of AI “Franken monster” directly to lower ROI even when individual teams benefit from being able to move faster
Security and compliance become much harder to coordinate
Tribal knowledge lives with individual team members and is lost when they leave
When you look at all the data, the TL;DR seems to be:
Centralize the platform, governance, and standards. Decentralize the use-case ideation, workflow integration, and experimentation queue.
My point of view
I’ve been thinking a lot about this topic since I started at Sequel.io last fall. We’re at an interesting inflection point as a company — strong product-market fit and growing incredibly quickly, but no existing, established AI implementation structure. So, we have an opportunity to build it right from the start.
Based on my research, as well as my experience building with AI at both Sequel.io and Pavilion (where I led go-to-market for 3 years prior to joining Sequel), I believe in the need for centralized AI governance.
Here’s what I think that means in practice for marketing:
Someone needs to own the foundation. Your AI training documents (buyer personas, ICP documentation, brand voice guidelines, voice-of-customer research, customer proof points, etc.) have to live in one place, be maintained by someone, and be accessible to everyone building on top of them. If everyone on the team is each running their own AI tools using different versions of your buyer persona, at best your results will be inconsistent and at worst they won’t be usable.
Someone needs to own the architecture. The tools your team builds need to talk to each other. The competitive intelligence workflow should inform the campaign workflow should inform the content workflow should inform the sales enablement workflow. That interoperability requires someone thinking about the stack — what tools are connected, how data flows between them, where the sources of truth live, and what happens when something breaks. This doesn’t have to be a full-time role, but it has to be someone’s job.
Someone needs to own the security posture. Having worked as a CMO for a couple of cybersecurity companies, this is the one that keeps me up at night. Most AI tools built inside marketing departments were built fast and shipped without a security review. Credentials are stored in environment files on laptops, API keys are pasted into automation workflows with insufficient access controls, and customer data flows are undocumented. When a breach happens (and eventually one inevitably does), you need to be able to quickly identify who built your AI solutions, how they work, and what they have access to. If no one can answer those questions, there’s a good chance the cost of the investigation alone will dwarf whatever you saved by not buying software with a proper security review built in.
The building itself should be decentralized. And this is where I push back on the conventional AI governance instinct. The person on the content team who does competitive analysis every Monday morning is the person who knows exactly which parts of that process are inefficient and which require a human in the loop. If she’s at all AI-forward (and I would argue that every marketer needs to be these days), then she’s the right person to build the tool that automates the inefficient parts. The exception to this are technically complex builds that require specialized programming or support.
The operating model I’ve found works — and that the research seems to support — centralizes the foundations and the governance, distributes the building, and designates someone responsible for identifying what’s working and making it available to the broader team.
That last part is important, so I’ll say it again.
To achieve compounding results with decentralized or federated AI, you must designate someone responsible for identifying what’s working and making it available to the broader team
One of the examples I came across in my research tells the story better than I can. BBVA rolled out centralized AI governance with distributed AI creation, resulting in 20,000+ custom GPTs built by employees across the organization, with 83% weekly active usage and about 3 hours saved per employee per week. The key to their success was the combination of secure, centralized enterprise AI access plus leadership training that reduced “shadow AI” (those uncontrolled, unsanctioned experiments and use cases that don’t scale) while enabling decentralized experimentation.
How this changes as your company scales
The right balance between centralization and decentralization is not static. It changes with your company’s AI maturity, headcount, regulatory environment, and the level of AI sophistication of the people on your team.
At the seed and early Series A stage, you almost certainly don’t have the resources or the use-case volume to justify a dedicated AI governance function. The right model here is usually to pick one person to own the foundation (the shared knowledge bases, tool inventory, and security practices), let everyone else build, and establish the habit of documentation from the start. Documentation sounds boring but it’s what separates early-stage teams that scale their AI programs from those that have to start over every time someone leaves. BNY Mellon’s AI Hub model, which produced 125+ live use cases and a 75% reduction in legal review time, started with exactly this kind of central ownership of the platform and distributed creation.
At the growth stage, you have more people, more tools in production, more customer data flowing through workflows, and more regulatory scrutiny. This is where the federated model becomes necessary. You need a person or small team that owns the AI platform(s) and controls model access, shared components, evaluation standards, and security protocols. You also need domain owners within marketing who own their function’s AI roadmap, measure it against their KPIs, and are responsible for what their team ships. At this stage, the centralized funtion stops doing the work and focuses on enablement.
At scale, the data from McKinsey and BCG suggests that the most successful organizations treat the operating model as a progression, starting with centralized governance and platform services, with selective decentralization as teams mature and demonstrate they can own more of the stack. The “graduation criteria” determines which teams earn the right to own their AI model endpoints and deployment budgets.
The common thread across all three stages is the importance of standardizing identity, access, monitoring, evaluation, and incident response before decentralizing. Decentralize before that and you end up with what McKinsey’s researchers call “parallel solutions” — the same infrastructure built five times, with five different security postures, by five people who had no way of knowing the others were working on the same problem.

Why expertise in the driver
The centralization versus decentralization debate is really a debate about where expert judgment should live.
If expert judgment is in compliance, security architecture, and platform engineering, it should be centralized — because those are the things that break catastrophically and expensively when they’re wrong.
If expert judgment is workflow knowledge, experimentation intuition, and domain expertise, it should be distributed — because those are the things that produce compounding value when they’re close to the work.
Most marketing teams have plenty of the second kind of judgment and very little of the first. That asymmetry should shape how you structure your AI program.
Bring in or develop the platform-level expertise you’re missing, while protecting the domain expertise you already have by giving it the tools and access to build.
The companies getting this right are the ones striking a delicate balance where AI implementation is rigorous enough to be secure, but distributed enough to be fast.
That’s the standard. It’s achievable, and the window to get there on your own terms, before external governance forces the question, is still open.
Sources referenced in this issue:
(Feeling lots of deja vu from my college days when I would crack open the Chicago Manual of Style to remember how to format a footnote - does that make me sound old?)
BCG and BCG Platinion, *Federated Data Governance Model* (2025)
McKinsey, *The gen AI operating model: A leader’s guide* (2024)
BCG, *The Nordic AI Inflection Point: Value Creation or Value Bubble?* (2025)
McKinsey, *The gen AI operating model: A leader’s guide* (2024)
Airbnb Engineering, “At Airbnb, Data Science Belongs Everywhere” (2015); “How does Airbnb track and measure growth marketing?” (2026)
Uber Engineering, “From Predictive to Generative: How Michelangelo Accelerates Uber’s AI Journey”
Spotify Engineering, “Unleashing ML Innovation at Spotify with Ray” (2023)
Netflix / Outerbounds, “Reasonable Scale Machine Learning with Open-Source Metaflow”
McKinsey, *The State of AI: How Organizations Are Rewiring to Capture Value* (2025)
💜A note on my content:
Yes, I use AI to help me write this newsletter. Every idea, insight, and point of view here is mine. AI helps me think, structure, and draft — it does not replace my judgment. I also use em dashes (and emojis 👀) unapologetically, sometimes because AI likes them, and sometimes because they’re grammatically correct. If you’re here to sniff out “what was written by AI,” you’ll probably be disappointed. And if you’re fundamentally against the use of AI in writing, this newsletter is likely not for you. You’ll find this disclaimer in every issue, because transparency matters to me.